How I Test AI Humanizers in 2026 (My Meaning-First Framework)


AI humanizers are everywhere in 2026. Most promise to make AI-generated text “sound human.” Very few explain what they change, what they break, or how to test them responsibly.
After testing 30+ AI humanizers over the last year, I stopped caring about one thing almost entirely: detector scores.
Instead, I evaluate AI humanizers using a meaning-first framework, because clarity, accuracy, and voice matter far more than whether a paragraph turns green in a scanner.
This article explains exactly how I test AI humanizers in 2026, the benchmarks I use, and why some popular tools fail quietly even when they “pass.”
Why “human score” stopped being useful
Here’s what I kept seeing in real tests:
- The same paragraph passes one detector and fails another
- Aggressive rewriting introduces subtle factual drift
- Text sounds “smooth,” but no longer sounds like me
- Longer outputs degrade faster than short samples
You can see a live demo of how different AI detectors respond to the same text in this video -
So instead of asking “Does this bypass detection?”, I ask:
Does this improve the writing without changing the meaning or voice?
That single question filters out most tools instantly.
My 2026 testing setup (simple but strict)
Every tool gets tested on the same three input types:
- SEO-style blog paragraph (conversational, informational)
- Academic / explanatory paragraph (structured, neutral tone)
- Personal narrative paragraph (voice-heavy, opinionated)
Each input is 150–300 words: long enough to expose patterns, short enough to compare fairly.
The 6-point meaning-first benchmark
Each humanizer is scored qualitatively (High/Medium/Low) on six dimensions:
1. Meaning preservation (non-negotiable)
Does the core argument stay intact? Are examples, claims, and intent unchanged?
This is where tools like Quillbot consistently perform well. In my tests, Quillbot rephrased sentences for clarity without quietly altering claims, which makes it reliable for editing drafts you already trust.
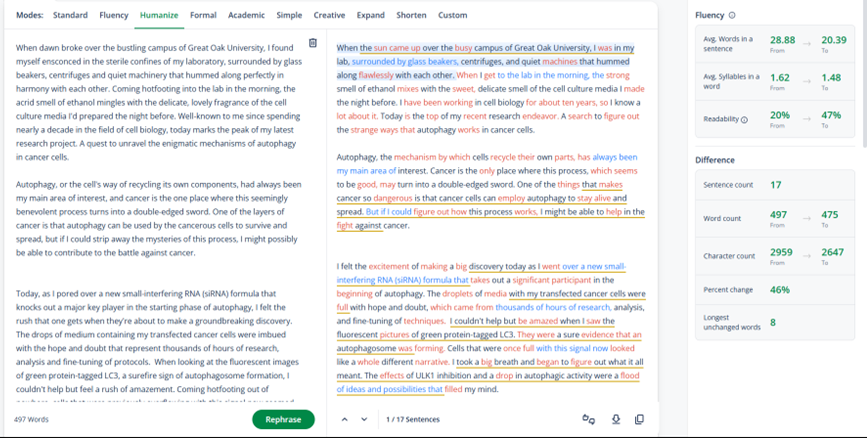
2. Voice control
Can the tool maintain a consistent tone across paragraphs, or does everything collapse into the same neutral cadence?
In long-form tests, GPTHuman.ai stood out here. When I ran 800–1,200 word blog sections through its Balanced and Enhanced modes, the structure improved without flattening the voice, as long as I followed up with a short human edit.
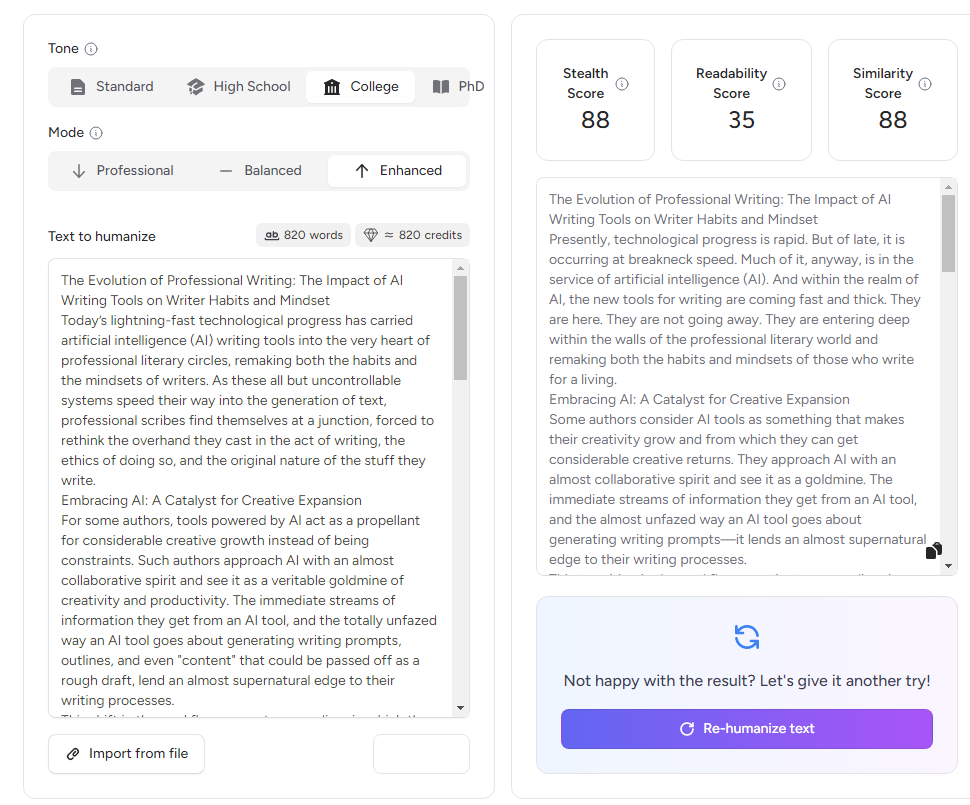
3. Readability improvement
Does the output actually read better to a human?
Some tools technically “humanize” text but make it harder to read by:
- Overusing academic phrasing
- Stretching sentences unnecessarily
- Replacing simple words with abstract ones
In budget-tier tools like WriteHuman AI, I noticed a trade-off: sentence variation improved, but readability sometimes dipped slightly. This is something a quick read-aloud can easily fix.
4. Over-paraphrasing risk
This is the single most-overlooked flaw in AI humanizers. Over-paraphrasing shows up as:
- Thesaurus-heavy word swaps
- Unnatural phrasing
- Loss of specificity
Tools that rewrite too much often score worse here, even if they look impressive at first glance. In my tests, this risk increased sharply when processing longer inputs (>1,000 words).
5. Factual drift
Does the tool introduce new ideas, implied claims, or softened certainty?
This matters most in academic and explanatory content. In all-in-one platforms like EssayDone.ai, I found the workflow convenient, but aggressive humanization occasionally shifted emphasis or phrasing enough that I had to manually re-check arguments.
That’s not a flaw if you expect it, but if you don't, it can be dangerous.
6. Editing time required
The final test is practical:
How long does it take to make this publishable?
If a tool saves 10 minutes but adds 15 minutes of cleanup, it fails — no matter how “human” the output looks.
In 2026, the best tools consistently reduce editing time to 10–15 minutes per section, not zero.
What I learned after testing 30+ tools
Three patterns became obvious:
- No tool preserves meaning perfectly at scale. The longer the input, the higher the risk.
- Light editing beats heavy rewriting. Tools that edit outperform tools that transform.
- Humanizers work best late in the workflow. Outline → draft → humanize → human edit. Not the other way around.
The rule I follow now
I only use AI humanizers on text I already understand and can defend.
If I wouldn’t stand by a paragraph in my own voice, no tool gets to “fix” it for me.
That’s also why, in my main comparison of AI humanizers for 2026, I prioritize tools that support writers rather than replace them, and why I focus more on meaning preservation than detector outcomes.
Final takeaway
In 2026, the best AI humanizer isn’t the one that promises 100% bypassing AI detector tools. It’s the one that respects meaning, supports voice, and reduces friction — while leaving accountability where it belongs: with the writer.
If you’re curious how this framework plays out across specific tools, I’ve documented my full side-by-side testing and results in my main AI humanizers comparison.
Affiliate disclosure: This article contains affiliate links. If you purchase a subscription through these links, I may earn a small commission at no extra cost to you. Thank you for supporting my work!